Object vs Block vs File Level Storage Protocols
For the past four weeks, I have been at IBM Research digging down deep into the wild depth that is cloud storage. Before my internship, the closest I got to cloud computing was learning about computer networking, and I never imagined myself spending 8+ hours a day working on cloud storage systems. Well, flash forward to the current time, where I am so close to file level cloud storage that I actually have to consult an engineer that implemented some major capabilities of the NetApp filers, because documentation only reaches so far.
So, what exactly are object, block, and file level storage?
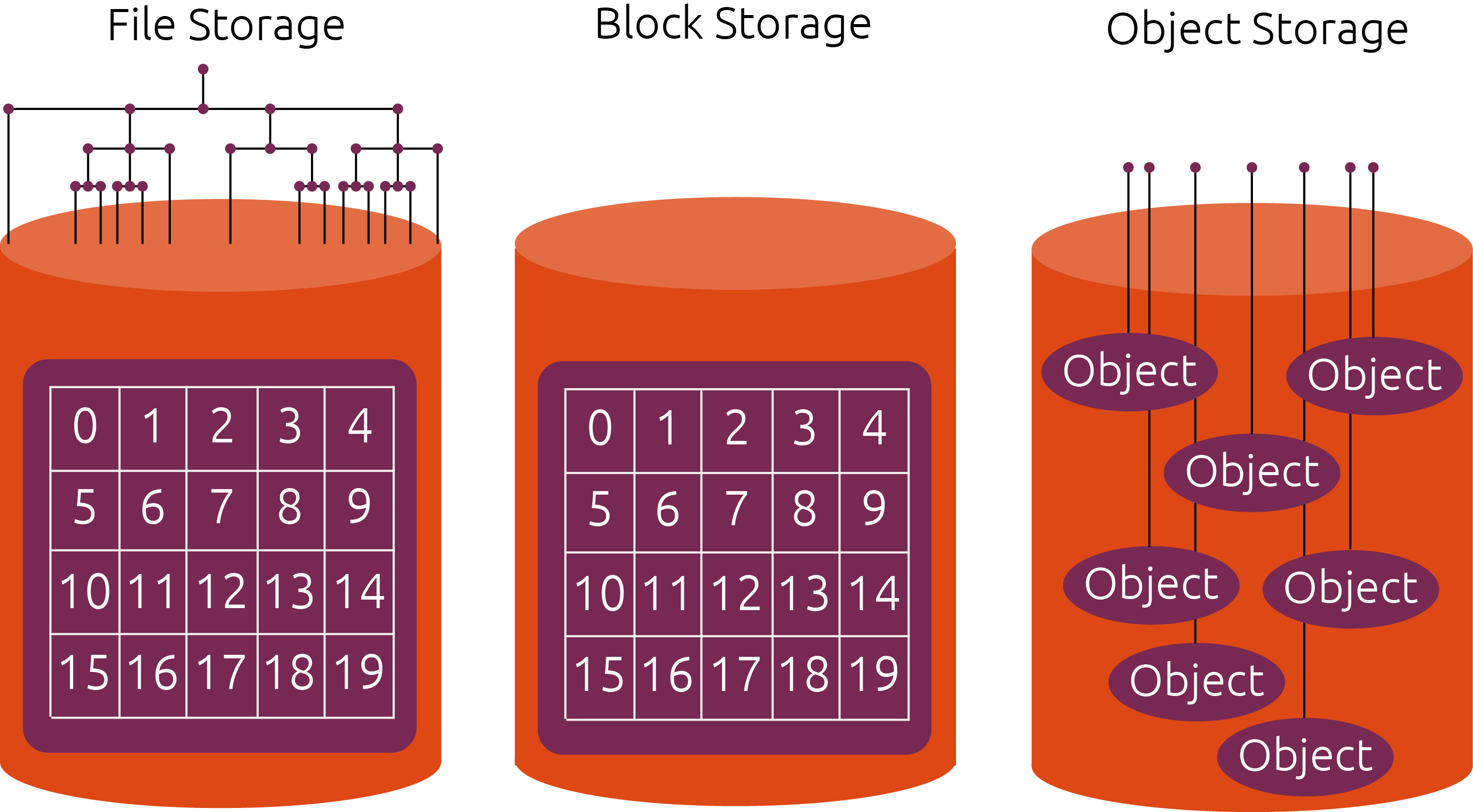
File Storage
Probably the most well-known storage type: file level storage. Files are whole pieces of data with decently descriptive metadata (size, owner, permissions, etc) stored in a hierarchy like a file system.
Block Storage
A block of data is simply a chunk. You can break up a file into many blocks, and combine them all to build to the file again. Blocks have no metadata stored with with, but they do have an address by which they are accessed. Block storage really relies on the software layer that is managing it, because blocks have no meaning unless they are combined in specific ways.
Object Storage
Objects are similar to blocks, except the chunks' metadata is stored with it, forming an object. An object has a specific ID dependent on the information stored, similar to hashing, and objects are stored in flat address space. What makes object storage neat is the metadata and the flat addressing: you can assign any information you want to the object, and you can add some fantastic software managing support that applies a virtual hierarchy to the objects.